If you are curious about how data science projects actually get done, you have probably wondered: what is data science workflow? Simply put, a data science workflow is a structured process that guides teams through each phase of a data project. It helps everyone stay organized, prevents missed steps, and builds trust that the results are repeatable and reliable. In this article, you will learn what a typical workflow looks like, why it matters, and which practical tips and tools can make your next data project more successful.
What is data science workflow and why is it important?
A data science workflow is a step-by-step framework outlining how data science projects move from an initial question to a final solution. It acts like a roadmap for tasks such as collecting data, cleaning it, analyzing, building models, and sharing results. This structure is key for project success because it fosters teamwork, keeps efforts organized, and makes it easier to repeat or improve previous work as needed.
In modern data-driven companies, using an established workflow means everyone knows what to expect and when. It reduces confusion and helps avoid missing important details. For instance, if a team is investigating customer trends, following a workflow ensures they start with a clear objective, get the right data, clean and analyze that data, and finally share their findings in a useful way.
What are the main steps in a typical data science workflow?
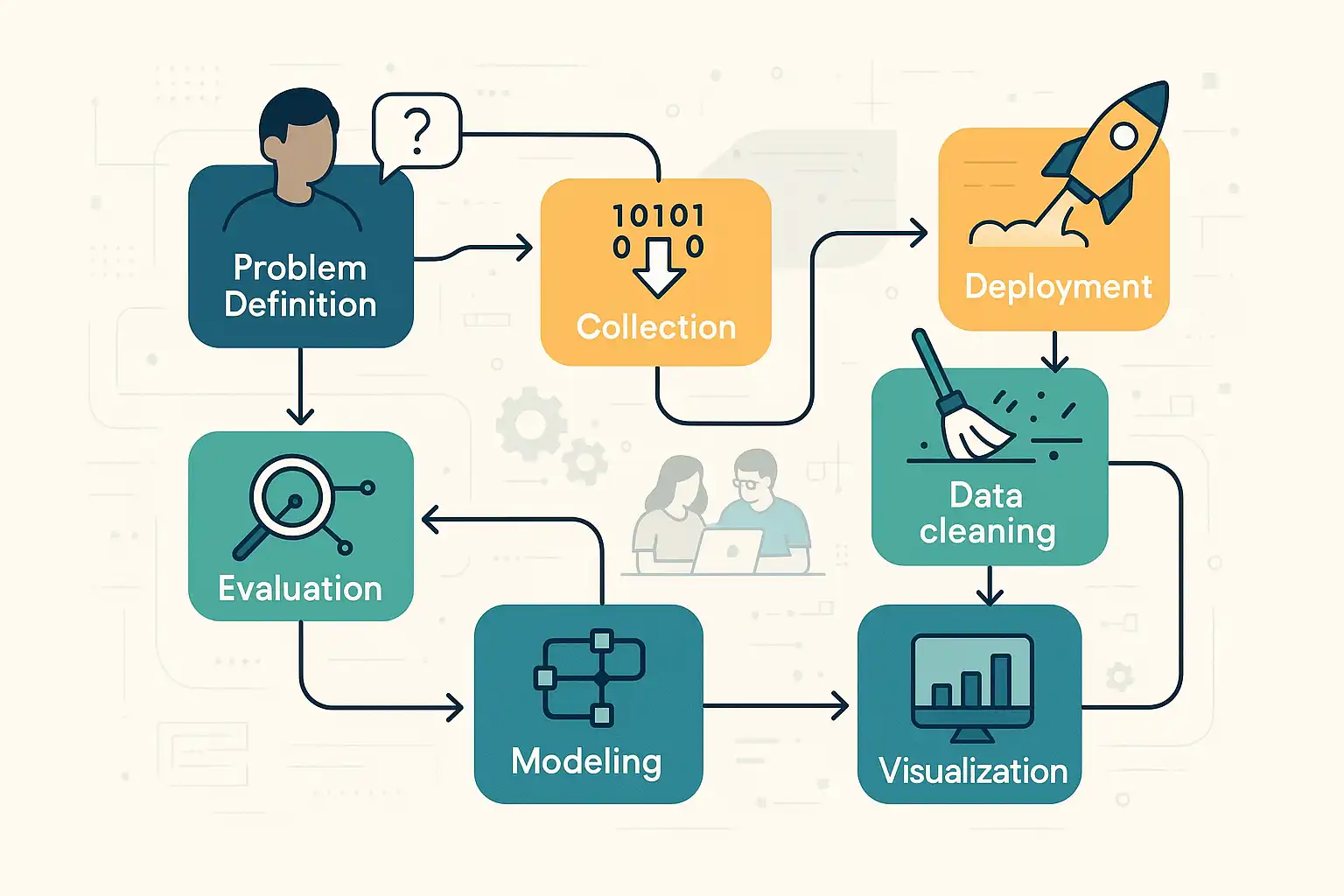
Most data science workflows are built on similar phases, even if the details differ. Frameworks like CRISP-DM, OSEMN, and those used by universities all share common steps. Here is a straightforward outline:
- Define the Problem: Clearly state what you are trying to solve or understand. For example, “Can we predict which customers will leave next month?”
- Collect Data: Gather the raw data required to answer your question. This might mean pulling data from databases, APIs, or files.
- Clean and Prepare Data: Fix errors, handle missing values, and organize the data. This ensures the next steps are built on solid ground.
- Explore and Analyze: Use descriptive statistics, charts, and simple models to understand the data’s patterns and quirks.
- Model Building: Apply machine learning, statistical methods, or other models to find deeper patterns or make predictions.
- Evaluate Results: Check how well the model or analysis answered the original question. Was it accurate? Did it make sense?
- Communicate and Visualize: Share findings with others using clear charts, dashboards, or reports.
- Deploy and Monitor: If your result is a tool or prediction, put it into real-world use and watch how it performs over time.
Some frameworks add or merge steps, but the essence remains: a series of practical phases that move from problem to insight to action. Remember, these phases are not always strictly linear—often, teams loop back to previous steps to refine or adjust their work.

Which tools help at each stage of the workflow?
Every step in the data science workflow is easier and more efficient with the right tools. Here’s a look at common options for each phase:
- Defining the Problem: Brainstorming software (like Miro or Google Docs), project management tools (Trello, Asana), and clear communication using emails or chat apps.
- Collecting Data: SQL databases, Python scripts, Excel, data connectors, APIs, or web scraping tools (such as BeautifulSoup).
- Cleaning and Preparing Data: Python (with Pandas or NumPy), R, OpenRefine, or tools built into platforms like IBM Watson Studio.
- Exploring and Analyzing: Jupyter Notebooks, RStudio, data visualization tools (Tableau, Power BI, Matplotlib), and summary statistics packages.
- Model Building: Machine learning libraries like scikit-learn, TensorFlow, PyTorch, or cloud-based tools like Google Cloud ML or Amazon SageMaker.
- Evaluating Results: Metric and reporting libraries, A/B testing tools, and cross-validation frameworks.
- Communicating and Visualizing: Dashboards (Tableau, Power BI), static or interactive web apps (Streamlit, Dash), and traditional slides or reports.
- Deployment and Monitoring: MLOps tools (MLflow, Kubeflow), cloud deployment platforms, and model monitoring dashboards.
Choosing tools often depends on your team’s background, the project’s complexity, and available budget. For many projects, open-source software and cloud platforms can offer powerful solutions without large up-front costs.
How can best practices improve your data science workflow?
Even with the best tools, a successful data science workflow relies on strong habits. The following best practices help make your workflow more efficient and your results more trustworthy:
- Start with a clear objective: Define your project’s goal before gathering or analyzing data.
- Document each step: Keep track of decisions, data sources, and code. Documentation helps team members collaborate and allows others to reproduce your work later.
- Communicate early and often: Regular check-ins prevent misunderstandings and help catch issues early.
- Validate assumptions: Before jumping into modeling, test your ideas with quick data checks and basic analyses.
- Embrace iteration: It is normal to revisit earlier steps as you learn more from the data, so expect and plan for adjustments.
- Monitor performance: If your analysis or model is used long-term, keep tracking its performance and adapt when necessary.
When collaborating with specialists in data science fields, such as NLP and Computer Vision Experts, adopting these habits can streamline teamwork and help produce reliable results, whether you are working on natural language processing, image analysis, or predictive modeling tasks.
What are some common data science workflow frameworks?
Several recognized frameworks shape the way teams approach data projects. Here are the most widely used ones:
- CRISP-DM (Cross Industry Standard Process for Data Mining): Probably the most famous, CRISP-DM guides teams from business understanding through data prep, modeling, and deployment. It emphasizes repeatable cycles and feedback.
- OSEMN: Pronounced like “awesome,” OSEMN stands for Obtain, Scrub, Explore, Model, and Interpret. It is easy to remember and works well for fast-moving projects.
- Harvard Data Science Workflow: This framework highlights the importance of reproducibility (making sure others can repeat your results) and communication, in addition to classic data science steps.
- Team-customized workflows: Many organizations adapt these frameworks to fit their unique processes, blending elements or adding extra steps based on their needs.
While all these workflows cover similar ground, the main difference lies in how much they emphasize looping back between steps, documentation, and team communication. Choosing a framework that suits your team’s culture and project needs is essential for smooth progress.
How to choose and adapt the right workflow for your project?
Picking the right workflow starts with considering your team’s expertise, project complexity, and stakeholder needs. For short, exploratory tasks, a simple checklist may be enough. For multi-month, high-stakes projects, a detailed workflow (like CRISP-DM) with defined deliverables at each step can save time and avoid costly mistakes.
When adapting a workflow, involve your team early. Agree on when to meet, how to document results, and who is responsible for each phase. This up-front clarity keeps everyone on the same page and makes it easier to adjust if plans change.
Tips for successful adaptation:
- Start small and reflect: Pilot the workflow on a modest project, then gather feedback before scaling up.
- Customize responsibly: Add or remove steps only if there is clear value. The core logic of moving from question to result should remain.
- Focus on communication: Regularly update all stakeholders, even if nothing has changed. Transparency builds trust and helps catch issues early.
Incorporating these ideas leads to a process that works for your team, reduces confusion, and maximizes impact.

FAQ: Data Science Workflow Essentials
- What is the difference between a workflow and a data pipeline?
- A workflow is the full set of steps in a project, from planning to deployment. A data pipeline usually refers to the technical part of moving and transforming data, often automated, and is just one phase of the workflow.
- Can I skip steps in the workflow?
- While some small projects may not require every step, skipping key parts—like cleaning data or checking results—usually leads to errors or unreliable insights. It is better to scale back the scope than omit crucial steps.
- Which workflow step is most time-consuming?
- For most teams, cleaning and preparing data takes up the largest chunk of time. Messy or incomplete data can make later steps far more difficult, so investing effort early saves time in the long run.
- How do workflows help new data scientists?
- Workflows offer a clear guide for beginners, helping them avoid common mistakes and focus on high-impact work. Teams can also use workflows to train new members and document best practices for future use.